一、主要思路
-
1.利用截图软件
flameshot进行截取需要被文字识别的图片,并使用imagemagick对图片进行四倍放大; -
2.利用文字识别OCR软件
tesseract,进行识别; -
3.将识别到的结果输出,复制到文件和剪切板。
二、安装相关软件
需要安装的软件有:tesseract、tesseract-data-chi_sim、tesseract-data-chi_sim_vert、tesseract-data-chi_tra、tesseract-data-chi_tra_vert、tesseract-data-eng、imagemagick、gimagereader-gtk。
1.安装软件主体
(1)使用如下命令安装tesseract:
sudo pacman -S tesseract
(2)使用如下命令安装imagemagick,用于图片放大:
sudo pacman -S imagemagick
(3)安装tesseract前端GUI程序(可以不装,如果想用一下GUI,可以安装gimagereader-gtk或gimagereader-qt):
sudo pacman -S gimagereader-gtk
2.安装字库
tesseract支持60多种语言的识别,使用之前需要先下载对应语言的字库。
完整字库项目地址:https://github.com/tesseract-ocr/tessdata
这里我们只使用简体中文、繁体中文、英文三种字库:tesseract-data-chi_sim(简体中文字库)、tesseract-data-chi_sim_vert(简体中文垂直方向字库)、tesseract-data-chi_tra(繁体中文字库)、tesseract-data-chi_tra_vert(繁体中文字库垂直方向字库)、tesseract-data-eng(英文字库)、tesseract-data-osd(方向和脚本检测)、tesseract-data-equ(数学、等式检测)。安装命令如下:
sudo pacman -S tesseract-data-chi_sim tesseract-data-chi_sim_vert tesseract-data-chi_tra tesseract-data-chi_tra_vert tesseract-data-eng tesseract-data-osd tesseract-data-equ
三、制作[shell脚本]一键识别,并输出到文件和剪切板
在目录/home/dh/opt/tesseractOcr/新建后缀为.sh的shell脚本文件,例如命名为tesseractOcr.sh,并在同目录下新建文件夹目录/home/dh/opt/tesseractOcr/screenshot。
将以下代码复制到文档tesseractOcr.sh:
注意:将变量SCR路径部分替换成你想要存放截图以及识别结果txt文档的路径;
#!/bin/env bash
# Dependencies: tesseract imagemagick flameshot xclip(optional)
#Name: OCR Picture for Arch Linux
#Fuction: take a screenshot and OCR the letters in the picture
#Path: /home/Username/...
#you can only scan one character at a time
SCR_0="/home/dh/opt/tesseractOcr/screenshot/src_origin"
SCR="/home/dh/opt/tesseractOcr/screenshot/src"
SCR2="/home/dh/opt/tesseractOcr/screenshot/src2"
# before take a screenshot, if file "src.png" and "src_origin.png" exist, delete these two files
rm -f $SCR.png $SCR_0.png
## 截图后,直接放大并覆盖原始文件方法 Start
# take a shot what you wana to OCR to text, delay 2 seconds
#flameshot gui -p $SCR.png -d 2000
# increase the png, 亮度不变,色调重置为中性(即不会偏向红色、绿色或蓝色)
# mogrify 直接放大并覆盖原始文件
#mogrify -modulate 100,0 -resize 400% $SCR.png
# should increase detection rate
## 截图后,直接放大并覆盖原始文件方法 End
## 截图后,放大原始图像文件后,同时保留原始图像文件和放大后图像文件 Start
# take a shot what you wana to OCR to text, delay 2 seconds
flameshot gui -p $SCR_0.png -d 2000
# increase the png, 亮度不变,色调重置为中性(即不会偏向红色、绿色或蓝色)
# convert 放大原始文件,创建调整后图像,并保留原始图像
convert $SCR_0.png -modulate 100,0 -resize 400% $SCR.png
# should increase detection rate
## 截图后,放大原始图像文件后,同时保留原始图像文件和放大后图像文件 End
# OCR by tesseract
tesseract $SCR.png $SCR &> /dev/null -l eng+chi_sim+chi_sim_vert+osd+equ # 简体中文+英文
#tesseract $SCR.png $SCR &> /dev/null -l eng+chi_sim+chi_tra+chi_sim_vert+chi_tra_vert+osd+equ # 简体中文+繁体中文+英文
# get the text and copy to clipboard
#sed -i 's/[[:space:]]//g' $SCR.txt # 删除空格方式1
#sed -i 's/\ //g' $SCR.txt # 删除空格方式2
cat $SCR.txt | sed -r 's/([^0-9a-z])?\s+([^0-9a-z])/\1\2/ig'>$SCR2.txt # 解决每个汉字之间有空格的情况,英文单词间空格依旧保留
# if you use xclip as your clipboard, use this command:
#cat $SCR2.txt | xclip -selection clipboard
# if you use kde clipper as your clipboard, use this command:
getSCR2=$(cat $SCR2.txt)
qdbus org.kde.klipper /klipper setClipboardContents "$getSCR2"
# 设置一个陷阱来捕获EXIT信号
on_exit() {
# 在这里发送通知
notify-send "OCR识别结束" "已OCR识别完毕截取的图片,并已将识别文本复制到剪贴板,Ctrl+V粘贴即可!"
}
# 使用trap命令注册on_exit函数,以便在脚本退出时调用它
trap on_exit EXIT
# 使用exit命令退出脚本,这将触发on_exit函数并发送通知
exit 0 # 0表示成功退出
注意:中文识别情况下,有可能每个字之间都有空格,所以在脚本里添加了去除空格的代码。
添加运行权限
sudo chmod a+x tesseractOcr.sh
四、设置快捷键,一键调用shell脚本
打开系统设置,点击键盘–快捷键,右边顶部可看到+号,点击+号添加快捷键。
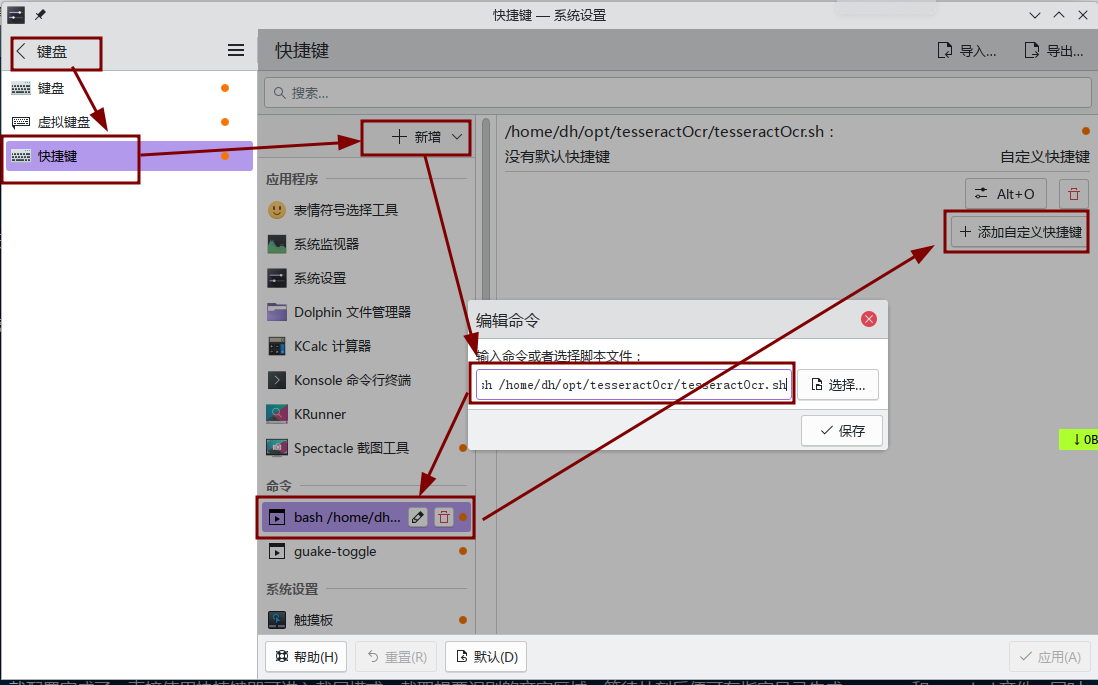
命令:bash 这里换成你自己shell脚本tesseractOcr.sh所在的路径;例如,我这里的bash命令为:
bash /home/dh/opt/tesseractOcr/tesseractOcr.sh
添加自定义快捷键时,不要与你系统中的其他快捷键冲突,我这里设置的快捷键是“Alt+O”
这样就配置完成了。直接使用快捷键即可进入截屏模式,截取想要识别的文字区域,等待片刻后便可在指定目录生成src.png和src2.txt文件,同时,文字会自动复制到剪切板,可以直接粘贴使用。
参考:
版权声明:本文由 Duter2016 在 2024年03月29日发表。本文采用CC BY-NC-SA 4.0许可协议,非商业转载请注明出处,不得用于商业目的。
文章题目及链接:《Arch Linux配置增强OCR文字识别功能》

